info
Currently, FHS has more than 600 conventional datasets that contain data collected from both the FHS core study and various ancillary studies. These datasets range from simple demographic and self-reporting data points to more complex multi-omic and digital data. In addition to these structured data, FHS has also been gathering unstructured data, especially in the recent years.
As depicted in the hierarchical flowchart below, FHS brain-related data can be broadly classified into structured and unstructured data, which can further divided into various categories. For structured data, they are available either at FHS or selected data-sharing sites (e.g., dbGAP, BioLINCC). Unstructured data are only at FHS.
- Figure 1
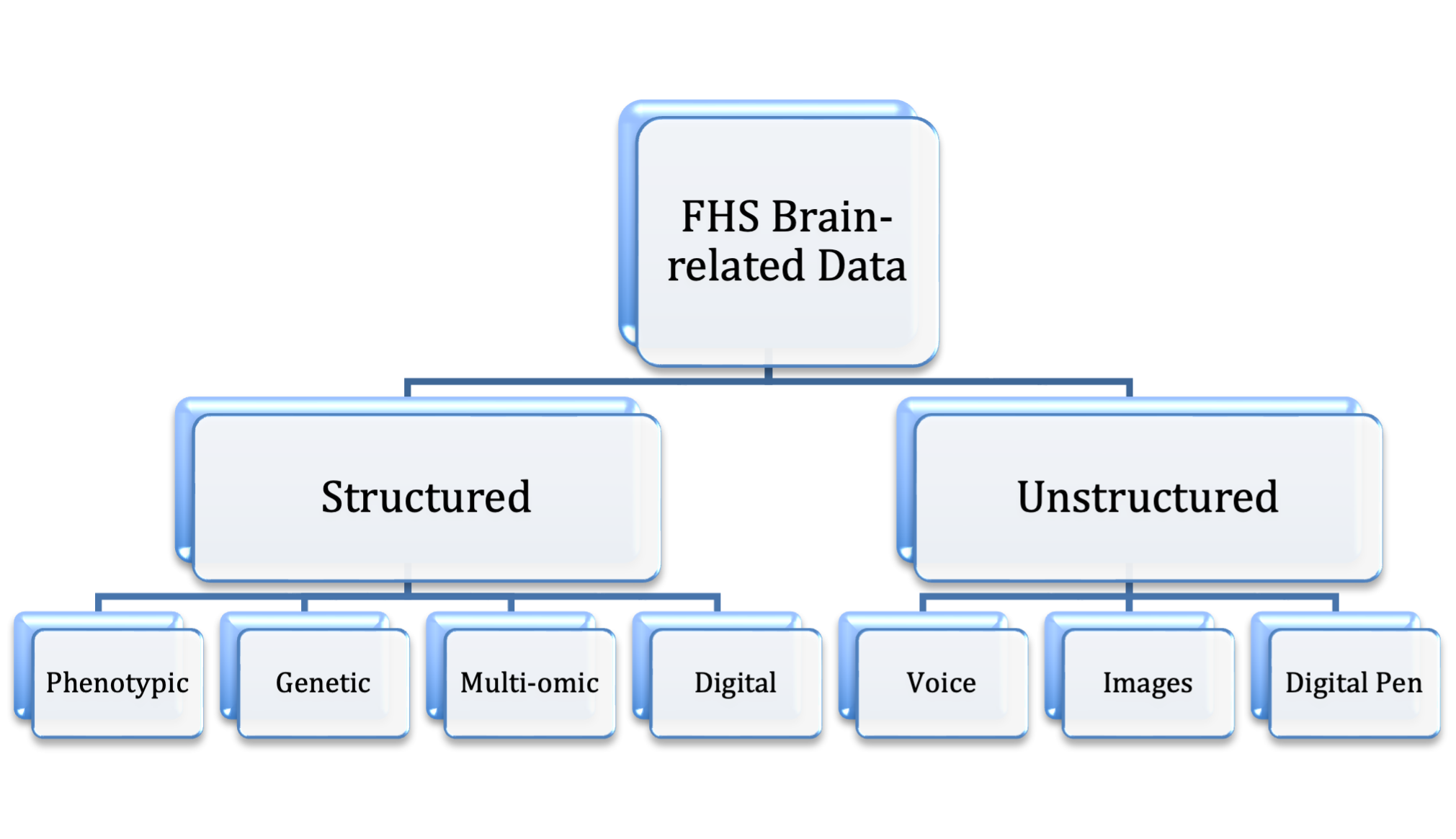
Structured Data
- Phenotypic Data The structured phenotypic data are commonly used data such as demographic, self-reported responses to questionnaires, clinical outcomes, lab test results, etc.
- Genetic Data DNA has been collected from blood and immortalized cell lines from Original Cohort, Offspring Cohort and the Third Generation Cohort (over 9,300 participants).
- Multi-omic Many of the multi-omic datasets comes under the SABRe projects – to identify the biomarker signatures of metabolic risk factors.
- Digital Unlike their unstructured counterparts, these digital data points are derived based on preset algorithms.
Unstuctured Data
- Voice Data Voice recording of neuropsychological assessment began in 2005, including raw voice recording, censored voice recording, and transcriptions.
- Image Data Image Data including Raw MRI brain scans (format DICOM) since 2002, and limited sample of the PET/Tau Scans.
- Digital Pen Including real-time pen motion recording during the digital clock drawing test, and other neuropsychological tests.